PythonとPlotlyでインタラクティブなコロプレス図を作成するではPlotlyでインタラクティブなコロプレス図を作成したが、ipywidgetsを使うとJupyter Notebook上にインタラクティブなウィジェットを作成できる。今回はe-Statからダウンロードした経済センサスのデータを使って、ドロップダウンウィジェットで項目を選択して表示項目を変えられるコロプレス図を作成してみる。
Windows10(1903)のWSL(Ubuntu 18.04)とJupyter Notebookを使用。
GeoPandas、Plotly、ipywidgetsをインストールする。それぞれpipでインストールできる。
バージョンはそれぞれ以下の通り。
さらに以下のコマンドも実行しておく。
e-Statにある平成28年経済センサス(活動調査)のデータを使う。e-Statにある平成28年経済センサス(活動調査)には分類や集計単位が異なるいくつかのデータがあるが、使用するのは以下のデータ。
Pythonとe-StatのAPIで統計データを取得するのようにAPIでもデータ取得できるが、今回はcsvをダウンロードする。e-Statでは項目を選択したり、表示形式を変更したりしてダウンロードできるが、今回は変更はせずにcsvダウンロード時に「注釈を表示する」のチェックを外した以外はデフォルトのまま。データ量が多いので2ファイルになる。
ダウンロードしたcsvの先頭の数行には統計名などデータの情報があり、その後にデータが部が続く。データは都道府県などの「地域」や「H28_産業分類」ごとのデータで、「H28_単独・本所・支所」と「表章項目」の2種類のカラムがある。
2つのcsvを取り込んで、最終的に「地域」「H28_産業分類」「H28_単独・本所・支所」の3つをインデックスとするマルチインデックスのDataFrameにする。
以下のようなデータになる。
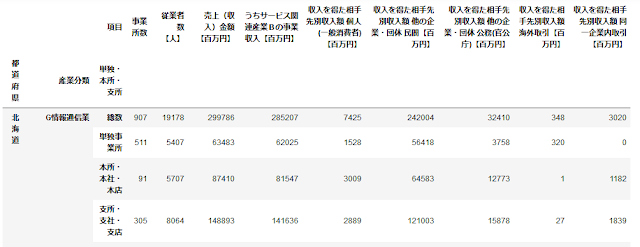
さらに、PythonとPlotlyでインタラクティブなコロプレス図を作成するで作成した、簡略化したGeoJSON形式の都道府県境界図(jpnmap_simplified.geojson)も使う。
コロプレス図の作成はPythonとPlotlyでインタラクティブなコロプレス図を作成すると同様だが、さらにウィジェットを使って表示項目などをインタラクティブに変更できるようにする。
ドロップボックスウィジェットとしてコロプレス図背景地図の「背景地図」、事業所数や従業員数などの「項目」、ラーメン店などの「産業分類」、事業所の本社・支店数などの「単独・本所・支所」の4つを作成する。なお、コロプレス図に使用するデータはすべて人口1000人あたりの数値とする。コードは以下の通り(経済センサスのcsvを読み込む関数は省略)。
次のようなコロプレス図とその左上にドロップボックスのウィジェットが作成された。
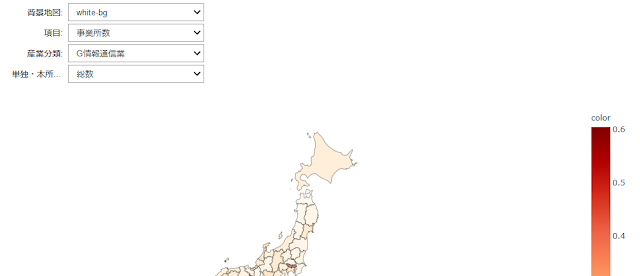
Jupyter Notebookで表示範囲が狭く見にくい場合は、メニューでCell>All Output>Toggle Scrollingとすると表示範囲が広くなる。
背景地図と産業分類を変更してみる。
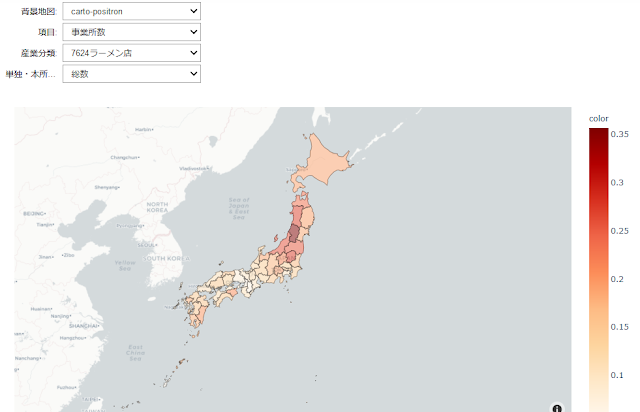
全体のコードはこちら。
環境
Windows10(1903)のWSL(Ubuntu 18.04)とJupyter Notebookを使用。
必要なライブラリのインストール
GeoPandas、Plotly、ipywidgetsをインストールする。それぞれpipでインストールできる。
バージョンはそれぞれ以下の通り。
さらに以下のコマンドも実行しておく。
使用するデータ
e-Statにある平成28年経済センサス(活動調査)のデータを使う。e-Statにある平成28年経済センサス(活動調査)には分類や集計単位が異なるいくつかのデータがあるが、使用するのは以下のデータ。
- 統計名:経済センサス‐活動調査 平成28年経済センサス-活動調査 事業所に関する集計 産業別集計 サービス関連産業Bに関する集計
- 表番号:7
- 表題:サービス関連産業B(細分類),単独・本所・支所(3区分)別民営事業所数,従業者数,売上(収入)金額及び収入を得た相手先別収入額―全国,都道府県
平成28年経済センサス(活動調査)については平成28年経済センサス‐活動調査を参照。ラーメン店やホテルなど様々な産業の事業所数や収入などのデータがある。経済センサスの産業はたくさんあるが、平成28年経済センサス‐活動調査 産業分類一覧に一覧がある。
ダウンロードしたcsvの先頭の数行には統計名などデータの情報があり、その後にデータが部が続く。データは都道府県などの「地域」や「H28_産業分類」ごとのデータで、「H28_単独・本所・支所」と「表章項目」の2種類のカラムがある。
2つのcsvを取り込んで、最終的に「地域」「H28_産業分類」「H28_単独・本所・支所」の3つをインデックスとするマルチインデックスのDataFrameにする。
import pandas as pd
def load_sensus7(path_to_csv):
print('*** Loading {} ***'.format(path_to_csv))
# 都道府県をインデックスとして読み込む
# 最終header行より前の行はスキップされる
df = pd.read_csv(path_to_csv, dtype=object, header=[10, 12], index_col=1, skipinitialspace=True, encoding='shift-jis')
# 地域コード、時間軸コード、時間軸、表章項目カラムを削除
df.drop(columns=df.columns[:4], inplace=True)
df.drop(columns=df.columns[1], inplace=True)
# 産業分類をインデックスに追加してマルチインデックスにする
df.set_index(df.columns[0], append=True, inplace=True)
df.index.set_names(['都道府県', '産業分類'], inplace=True)
# set_indexを使うとマルチカラムインデックスがシングルインデックスカラムになってしまうので再設定
df.columns = pd.MultiIndex.from_tuples(df.columns, names=['単独・本所・支所', '項目'])
# 「単独・本所・支所」カラムをマルチインデックスに追加
# stackを実行すると順番が変わるのでreindexで元の順番を維持させる
column_l = [lv1 for lv0, lv1 in df.columns]
column_sorted = sorted(set(column_l), key=column_l.index)
index_sorted = []
base_l = [base for base, item in df.columns]
base_sorted = sorted(set(base_l), key=base_l.index)
for pref, industry in df.index:
for base in base_sorted:
index_sorted.append((pref, industry, base))
df = df.stack(level=0).reindex(index_sorted).reindex(columns=column_sorted)
# 取り込んだデータのカンマを除去して数値に変換
df = df.applymap(lambda x: pd.to_numeric(x.replace(',', ''), errors='coerce'))
# NaNを0とする
# to_numericだとfloatになってしまうのでここでintにする
df = df.fillna(0).astype('int64')
# 「全国」の行を削除
return df.iloc[~(df.index.get_level_values(0) == '全国')]
def main(path_to_csv_l):
df = pd.DataFrame()
for path_to_csv in path_to_csv_l:
df = df.append(load_sensus7(path_to_csv))
display(df.head())
if __name__ == '__main__':
# ダウンロードしたcsvを指定
main(['FEH_00200553_200243012738.csv', 'FEH_00200553_200243012807.csv'])
以下のようなデータになる。
さらに、PythonとPlotlyでインタラクティブなコロプレス図を作成するで作成した、簡略化したGeoJSON形式の都道府県境界図(jpnmap_simplified.geojson)も使う。
ウィジェットとコロプレス図の作成
コロプレス図の作成はPythonとPlotlyでインタラクティブなコロプレス図を作成すると同様だが、さらにウィジェットを使って表示項目などをインタラクティブに変更できるようにする。
ドロップボックスウィジェットとしてコロプレス図背景地図の「背景地図」、事業所数や従業員数などの「項目」、ラーメン店などの「産業分類」、事業所の本社・支店数などの「単独・本所・支所」の4つを作成する。なお、コロプレス図に使用するデータはすべて人口1000人あたりの数値とする。コードは以下の通り(経済センサスのcsvを読み込む関数は省略)。
import json
import pandas as pd
import geopandas as gpd
import plotly.express as px
import ipywidgets as widgets
# 都道府県境界図のパス
OUTLINEMAP_PATH = 'jpnmap_simplified.geojson'
# コロプレス図の中心
CENTER = {'lat': 36, 'lon': 140}
def load_outlinemap():
outline = gpd.read_file(OUTLINEMAP_PATH, driver='GeoJSON')
# GeoJSON形式で保存するとGeoDataFrameのindexが保存されないので再設定する
# to_jsonのときにindexの値がIDとなるため
outline.set_index('ID', drop=False, inplace=True)
print(outline.info())
display(outline.head())
return outline
def main(path_to_csv_l):
def plot_choropleth(background, colname, **indices):
# 「産業」「単独・本所・支所」で対象データをしぼる
prefs_df = df.copy()
for idx_name, idx_value in indices.items():
prefs_df = prefs_df.iloc[prefs_df.index.get_level_values(idx_name)==idx_value]
# マルチインデックスの都道府県以外のindexを削除する(outlineとの計算でエラーになるため)
prefs_df.index = prefs_df.index.droplevel(prefs_df.index.names[1:])
# outlineとprefs_dfのindexをIDに合わせる
prefs_df.set_index('ID', drop=False, inplace=True)
# 人口1000人当たりの数値にする
prefs_df['color'] = prefs_df[colname] * 1000 / outline['JINKO']
# color: 表示対象の項目
# locations: geojsonのIDに対応する項目
# geojson: geojsonをdictに変換したもの。IDがふられている
fig = px.choropleth_mapbox(prefs_df, geojson=json.loads(outline['geometry'].to_json()), locations='ID', color='color',
title = '',
hover_name = 'PREF_NAME',
color_continuous_scale='OrRd',
mapbox_style=background,
zoom=3.5,
center = CENTER,
opacity=0.5,
labels={colname:colname}
)
fig.update_layout(margin={'r':10,'t':30,'l':10,'b':10, 'pad':5})
fig.show()
# 都道府県境界図の読み込み
outline = load_outlinemap()
df = pd.DataFrame()
for path_to_csv in path_to_csv_l:
df = df.append(load_sensus7(path_to_csv))
# 経済センサスのデータと都道府県境界図のデータを、都道府県名をキーにしてマージ
# dfにgeometryに対応するIDを設定
idx = pd.MultiIndex.from_tuples(df.index.values, names=df.index.names)
df = df.merge(outline[['PREF_NAME', 'ID']], left_on=df.index.names[0], right_on='PREF_NAME', how='left')
df.index = idx
print(df.info())
display(df.head())
# 背景地図のウィジェット
background = widgets.Dropdown(
options=['white-bg', 'carto-positron', 'carto-darkmatter', 'stamen-terrain'],
value='white-bg',
description='背景地図:',
)
# 項目用ウィジット
# PREF_NAMEとIDを対象外にする
item = widgets.Dropdown(
options=df.columns[:-2],
value=df.columns[0],
description='項目:',
)
# index項目用Dropdown作成
dropdown_indices = {}
level_n = df.index.nlevels
for level in range(1, level_n):
index_l = list(df.index.get_level_values(level).values)
index_l_u = sorted(set(index_l), key=index_l.index)
dropdown = widgets.Dropdown(
options=index_l_u,
value=index_l_u[0],
description=df.index.names[level] + ':',
)
dropdown_indices[df.index.names[level]] = dropdown
widgets.interact(plot_choropleth, background=background, colname=item, **dropdown_indices)
if __name__ == '__main__':
# ダウンロードしたcsvを指定
main(['FEH_00200553_200243012738.csv', 'FEH_00200553_200243012807.csv'])
次のようなコロプレス図とその左上にドロップボックスのウィジェットが作成された。
Jupyter Notebookで表示範囲が狭く見にくい場合は、メニューでCell>All Output>Toggle Scrollingとすると表示範囲が広くなる。
背景地図と産業分類を変更してみる。
全体のコードはこちら。
0 件のコメント:
コメントを投稿